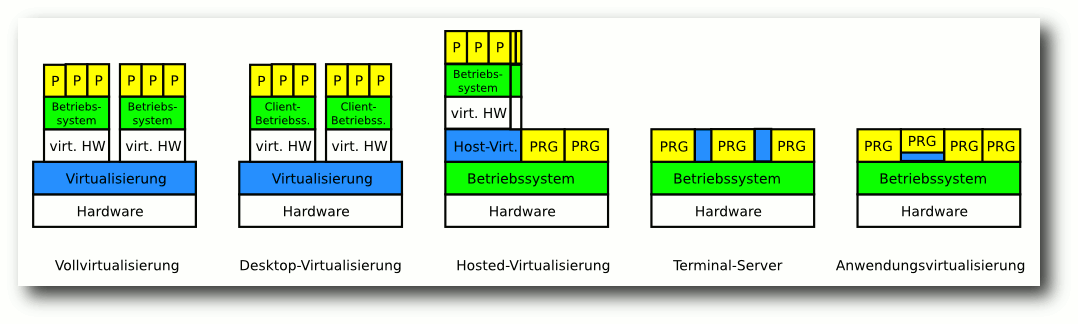
| Auszug von Virtualisierungslösungen | ||||
| VMware | Citrix | Microsoft | OpenSource | |
| Vollvirtualisierung | ESX3, ESXi3 | - | - | Bochs, Qemu etc. |
| Hardware-Assisted-Vollvirtualisierung | ESX, ESXi, VMware Server, VMware Workstation, .. | XenServer im Vollvirtualisierungsmodus | Hyper-V im Vollvirtualisierungsmodus | Xen und KVM (+Derivate) im Vollvirtualisierungsmodus |
| Paravirtualisierung | ESX + ESXi für Linux und spezielle Treiber | XenServer im Paravirtualisierungsmodus für Linux und spezielle Treiber | Hyper-V im Paravirtualisierungsmodus für Win2k8 und spezielle Treiber für z. B. Win2k3 | Xen und KVM (+Derivate)im Paravirtualisierungsmodus für Linux |
| Hosted-Virtualisierung | VMware Server, VMware Workstation, VMware Fusion | - | VirtualPC, XP-Mode in Windows7 | HXEN (Hosted Xen), VirtualBox OSE etc. |
| Terminal-Server | - | XenApp | Microsoft Terminal-Services | XDMCP, LTSP, FreeNX, |
| Desktopvirtualisierung | VMware View | XenDesktop | -1 | unbekannt |
| Anwendungsvirtualisierung | ThinApp | XenApp Streaming | Microsoft Desktop Virtualization (SCCM + App-V) | chroot, unionfs etc. |
| Client-PC-Betriebssystemvirtualisierung | VMware CVP22 | XenClient2 | - | - |
| Autoreninformation |
| Florian E.J. Fruth beschäftigt sich seit über drei Jahren intensiv mit Virtualisierungslösungen von VMware, Citrix und der Open-Source-Community. |
kwin: symbol-lookup error: /usr/lib/libkdeinit4\_kwin.so: undefined symbol: -ZTI26KDecorationFactoryUnstable |
| Autoreninformation |
| Martin Gräßlin ist KDE-Workspace-Entwickler und unter anderem Autor der Fensterdekoration Aurorae. |
| Autoreninformation |
| Mathias Menzer wirft gerne einen Blick auf die Kernel-Entwicklung, um mehr über die Funktion von Linux zu erfahren und seine Mitmenschen mit seltsamen Begriffen und unverständlichen Abkürzungen verwirren zu können. |
$ java -version java version "1.6.0_10" Java(TM) SE Runtime Environment (build 1.6.0_10-b33) |
java version "1.5.0" gij (GNU libgcj) version 4.3.2 |
class MyClass {
public static void main(String[] args)
{
System.out.println("Hello World");
}
// Dies ist ein einzeiliger Kommentar.
/* Dies ist ein Blockkommentar,
der ueber mehrere Zeilen geht.
*/
}
|
$ javac MyClass.java |
$ java MyClass |
class MyClass2
{
static String text="Hallo Welt";
}
|
System.out.println(MyClass2.text); |
$ javac MyClass.java $ javac MyClass2.java $ java MyClass Hallo Welt |
class Beispiel {
public static void main(String[] args) {
// Die Variable zahl1 wird deklariert.
int zahl1;
// zahl1 wird initialisiert es wurde
// ihr ein Wert zugewiesen.
zahl1 = 7;
// zahl2 wird in einer Anweisung
// deklariert und initialisiert.
int zahl2 = 3;
System.out.println(zahl1 + zahl2);
// Ausgabe: 10
System.out.println(zahl1 * zahl2);
// Ausgabe: 21
System.out.println(zahl1 / zahl2);
// Ausgabe: 2
// "double" ist genauer
double zahl3 = 7.0;
System.out.println(zahl3 / zahl2);
// Ausgabe: 2.33333...
}
}
|
class Person {
public String vorname;
public String nachname;
public void printName()
{
System.out.println(vorname+" "+nachname);
}
}
|
class Person {
public String vorname;
public String nachname;
public void printName()
{
System.out.println(vorname+" "+nachname);
}
public static void main(String[]args)
{
Person einePerson = new Person();
einePerson.vorname = "Hans";
einePerson.nachname = "Maier";
einePerson.printName();
}
}
|
class Mitarbeiter extends Person {
public int personalnummer;
}
|
| Autoreninformation |
| Raoul Falk programmiert Java und .NET an der Universität Duisburg-Essen. |
$ make $ make install |
(add-to-list 'auto-mode-alist '("\\.org\\'" . org-mode))
(global-set-key "\C-cl" 'org-store-link)
(global-set-key "\C-ca" 'org-agenda)
(global-set-key "\C-cb" 'org-iswitchb)
|
$ emacs example.org |
* erste Ebene ** zweite Ebene *** dritte Ebene |
#+TODO: TODO(t) NEXT(n) WAITING(w) SOMEDAY(s) DELEGATED(g) PROJ(p) | DONE(d) FORWARDED(w) CANCELLED(c) |
#TAGS: PHONE(o) URGENT(u) MAIL(m) |
#+TODO: IDEE(i) ENTWURF(e) FINAL(f) | DONE(d) CANCELLED(c) |
|
* Freies Magazin :LINUX:
- Artikel fuer Freies Magazin
- Autoren-Richtlinien (PDF)
:PROPERTIES:
:ARCHIVE: %s_freiesmagazin::
:END:
** PROJ Artikel ueber orgmode schreiben
DEADLINE: <2009-08-26 Mi>
*** ENTWURF Literaturverzeichnis [5/5]...
*** ENTWURF Linkliste [2/2]...
*** ENTWURF Warum orgmode...
*** ENTWURF Grundlegende Org-Mode Prinzipien...
*** IDEE Kopf frei machen...
*** IDEE Taegliche Nutzung...
*** IDEE Review...
|
|
*** ENTWURF Linkliste [2/2]
- [X] Orgmode.org
- [X] ThinkingRock GTD
- [2009-08-05 Mi] Linkliste in
OpenOffice.org muss mit
Literaturverzeichnis
kombiniert werden. |
|
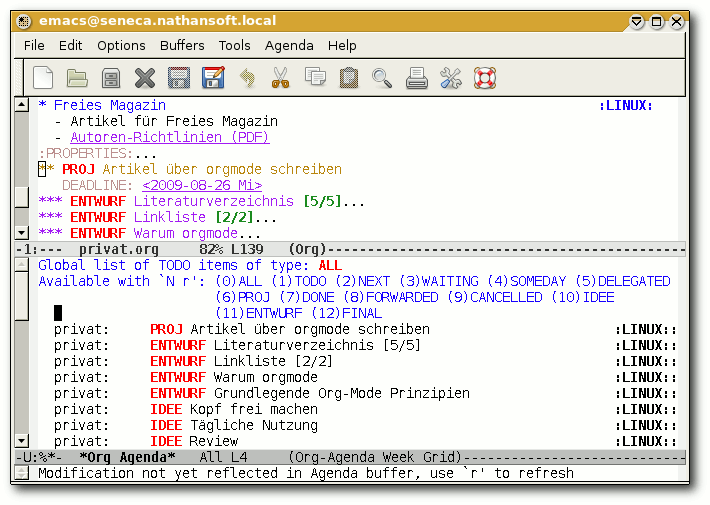
Global list of TODO items of type: ALL
Available with `N r': (0)ALL (1)TODO (2)NEXT (3)WAITING (4)SOMEDAY (5)DELEGATED
(6)PROJ (7)DONE (8)FORWARDED (9)CANCELLED (10)IDEE
(11)ENTWURF (12)FINAL (13)SKIPPED (14)COPIED
privat: PROJ Artikel ueber Org-Mode schreiben :LINUX::
privat: ENTWURF Literaturverzeichnis [5/5] :LINUX::
privat: ENTWURF Linkliste [2/2] :LINUX::
privat: ENTWURF Warum orgmode :LINUX::
privat: ENTWURF Grundlegende Org-Mode Prinzipien :LINUX::
privat: IDEE Kopf frei machen :LINUX::
privat: IDEE Taegliche Nutzung :LINUX::
privat: IDEE Review :LINUX:: |
|
Week-agenda (W33):
Mon 10 August 2009 W33
Die 11 August 2009
Mit 12 August 2009
privat: Sched. 4x: IDEE Kopf frei machen :LINUX::
privat: Scheduled: IDEE Taegliche Nutzung :LINUX::
privat: In 14 d.: PROJ Artikel ueber Org-Mode schreiben :LINUX::
Don 13 August 2009
Fre 14 August 2009
Sam 15 August 2009
privat: Scheduled: IDEE Review :LINUX::
Son 16 August 2009 |
|
Mit 12 August 2009
privat: Sched. 4x: IDEE Kopf frei machen :LINUX::
privat: Scheduled: IDEE Taegliche Nutzung :LINUX::
privat: (6/16): PROJ Artikel ueber Org-Mode schreiben :LINUX::
privat: In 14 d.: PROJ Artikel ueber Org-Mode schreiben :LINUX::
Don 13 August 2009 |
|
** TODO Spuelmaschine reinigen :RAINER:
SCHEDULED: <2009-08-15 Sa +12w>
- Siebe reinigen
- Maschinenpflege auf hoechster Stufe durchlaufen lassen |
|
Day-agenda (W33):
Sam 15 August 2009
privat: Scheduled: TODO Spuelmaschine reinigen :RAINER:
privat: Scheduled: IDEE Review :LINUX::
privat: (9/16): PROJ Artikel ueber Org-Mode schreiben :LINUX:: |
| Autoreninformation |
| Rainer König ist seit dem letzten Jahrtausend mit Linux unterwegs und arbeitet bei einem PC-Hersteller am Thema Linux-Hardware-Kompatibilität für PCs. |
$ man vim |
| Autoreninformation |
| Steve Klicek benutzt Linux seit Suse Linux 6.2, wobei z. Z. openSUSE seine erste Wahl ist. Den Editor Vim schätzt er als zuverlässigen Editor für seinen täglichen Umgang mit Linux. |
$ grep [Optionen] Suchmuster [Datei] |
$ grep --count ext2 /proc/filesystems |
$ grep --line-number audio /etc/group |
$ grep --with-filename --line-number --recursive root /etc |
$ ps aux |
$ ps aux | grep mplayer |
username 4057 2.3 2.8 67588 25504 tty1 S 17:06 1:54 gmplayer /home/username/Musik/xyz.mp4 username 5552 0.0 0.0 3204 768 pts/2 R+ 18:27 0:00 grep mplayer |
$ kill 4057 |
$ cat /var/log/Xorg.0.log | grep WW |
$ grep -e "^(WW)" /var/log/Xorg.0.log |
$ grep -e "^(WW)" -e "^(EE)" /var/log/Xorg.0.logo |
$ history | grep grep |
518 grep -e "^(WW)" -e "^(EE)" /var/log/Xorg.0.log |
$ !518 |
| Autoreninformation |
| Philipp Walther hat seine ersten Linux-Erfahrungen mit SUSE-Linux gemacht. Es folgten einige Jahre der Linux-Abstinenz. Nach einer Zeit des Experimentierens mit verschiedenen Distributionen ist er schließlich bei Debian GNU/Linux angekommen. |
| EAGLE-Icons | ||
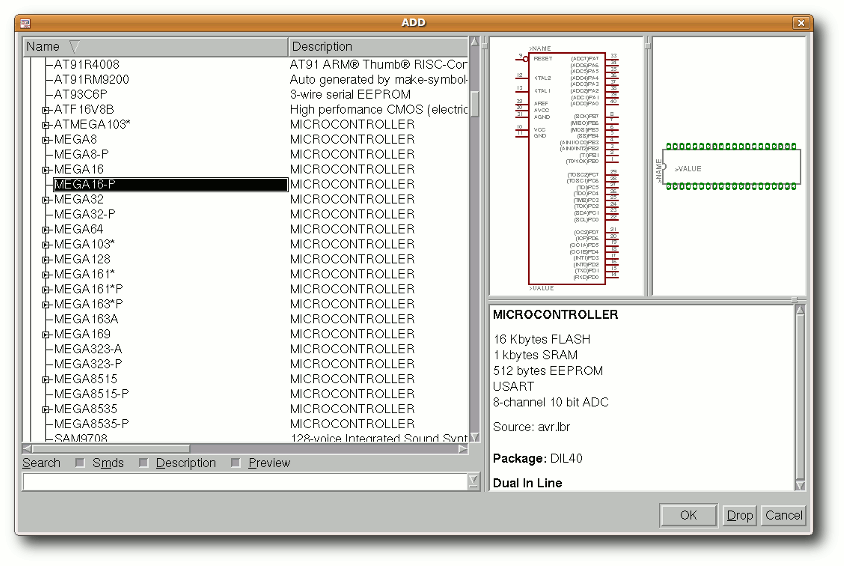
| „Add“ | Öffnet einen Auswahldialog, um Bauteile hinzuzufügen. | |
| „Auto“ | Startet den Autorouter. | |
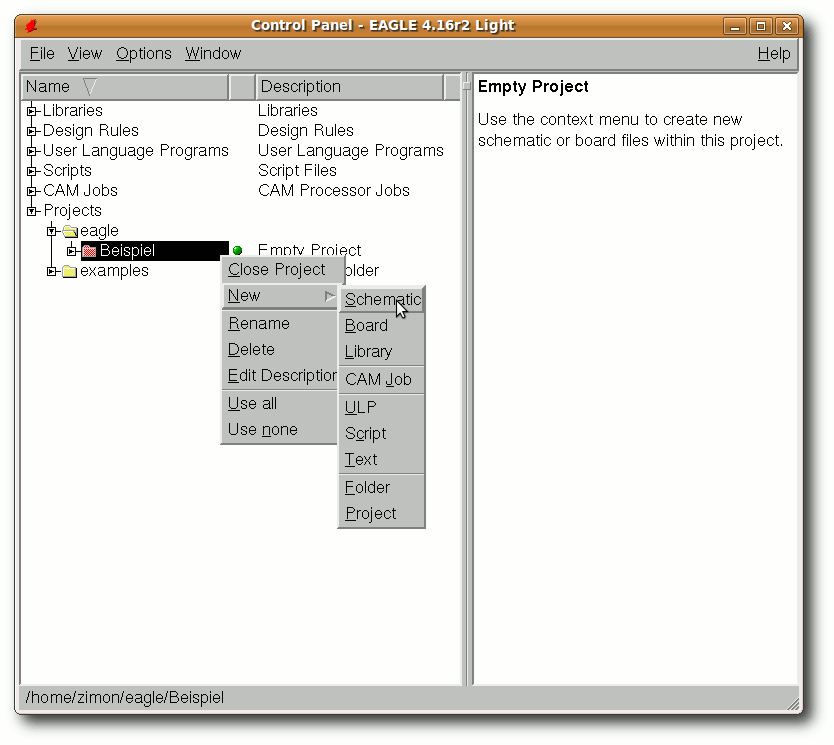
| „Board“ | Wechselt zur Boardansicht. | |
| „Bus“ | Werkzeug zum Generieren von Bussen. | |
| „Change“ | Mit diesem Tool können Eigenschaften von Bauteilen und anderen Elementen geändert werden. | |
| „Copy“ | Kopiert ein Bauteil. | |
| „Celete“ | Löscht ein Bauteil oder ein Netz. | |
| „Display“ | Öffnet einen Dialog, in dem man auswählen kann, welche Elemente wie angezeigt werden sollen. | |
| „Drc“ | Startet den Design Rule Check. | |
| „Erc“ | Startet den Electrical Rule Check. | |
| „Go“ | Wendet das ausgewählte Werkzeug auf alle Elemente an. | |
| „hole“ | Dient zum Vormerken von Bohrlöchern. | |
| „Info“ | Zeigt Informationen über Bauteile und Netze an. | |
| „Move“ | Werkzeug zum Verschieben von Bauteilen. | |
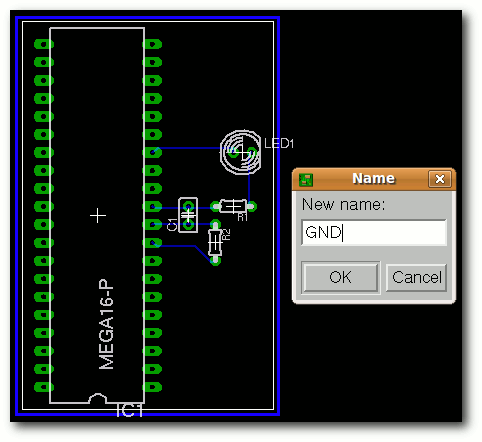
| „Name“ | Werkzeug zum Benennen von Bauteilen und Netzen. | |
| „Net“ | Werkzeug zum Zeichnen von Netzen. | |
| „Polygon“ | Werkzeug zum Zeichnen von Polygonen. | |
| „Ratsnest“ | Dieses Werkzeug optimiert die Verbindungen im Boardlayout. | |
| „Ripup“ | Werkzeug zum Auftrennen von Leitungen. | |
| „Route“ | Werkzeug zum Verlegen von Leitungen. | |
| „Show“ | Zeigt den Verlauf eines Netzes an. | |
| „Text“ | Werkzeug zum Setzen von Text auf den Schaltplan oder die Platine. | |
| „Ulp“ | Öffnet einen Dialog zum Starten von Benutzerskripten. | |
| „Value“ | Werkzeug, um Werte von Bauteilen einzustellen (z. B. den Wert eines Widerstands). | |
| „Via“ | Werkzeug zum Erstellen von Durchkontaktierungen. | |

$ povray -W800 -H600 dateiname.pov |
#local cam_x = 20; #local cam_y = 14; #local cam_z = -45; #local cam_a = 20; #local cam_look_x = 10; #local cam_look_y = 2; #local cam_look_z = 3; |

| Autoreninformation |
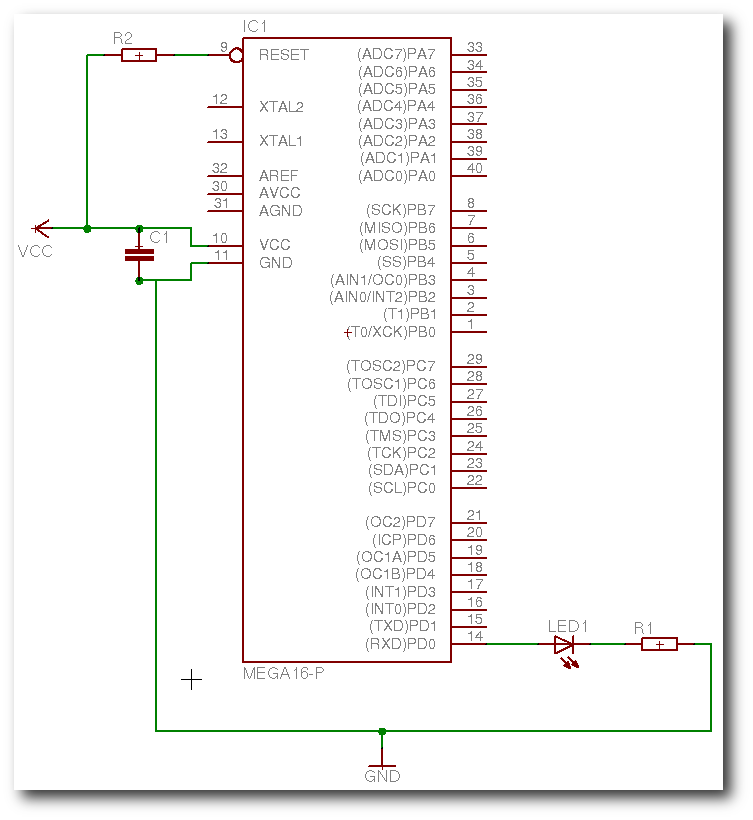
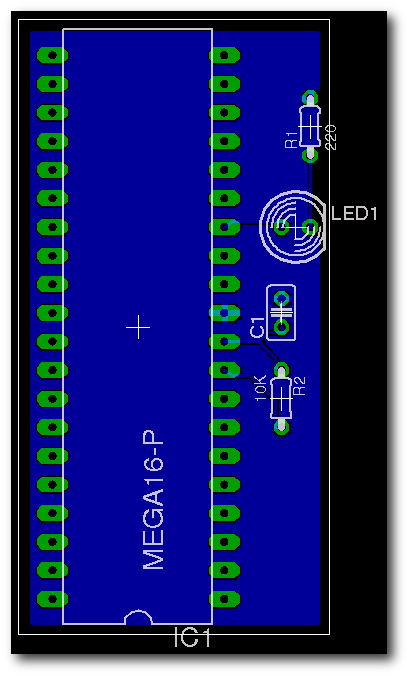
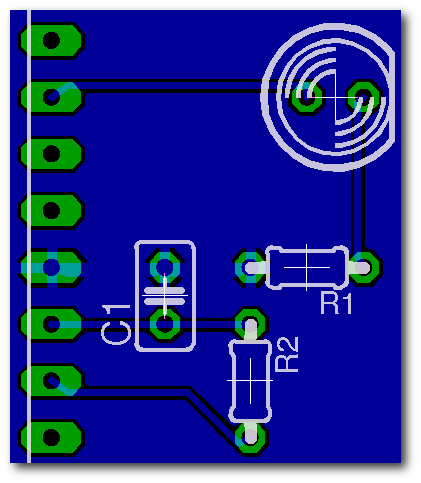
| Marcel Jakobs hat für viele seiner Projekte selbst Platinen entwickelt. Dafür nutzte er jedes Mal EAGLE. Die Bilder aus EAGLE3D haben schon in mancher seiner Arbeiten Verwendung gefunden. |
| Autoreninformation |
| Dominik Wagenführ ist unter anderem für das Layout in freiesMagazin zuständig, was mit LaTeX gesetzt wird. Aus dem Grund interessiert er sich auch immer für neue Pakete und Ansätze auf diesem Gebiet. |
| Karten | ||
| Titel | Anzahl | Wahrscheinlichkeit |
| Bewegung 3 Felder vorwärts | 400 | 0.071 |
| Bewegung 2 F. vorwärts | 800 | 0.143 |
| Bewegung 1 F. vorwärts | 1200 | 0.214 |
| Bewegung 1 F. rückwärts | 400 | 0.071 |
| Nach links drehen (90 Grad) | 1200 | 0.214 |
| Nach rechts drehen (90 Grad) | 1200 | 0.214 |
| Umdrehen (180 Grad) | 400 | 0.071 |
| Gesamt | 5600 | |
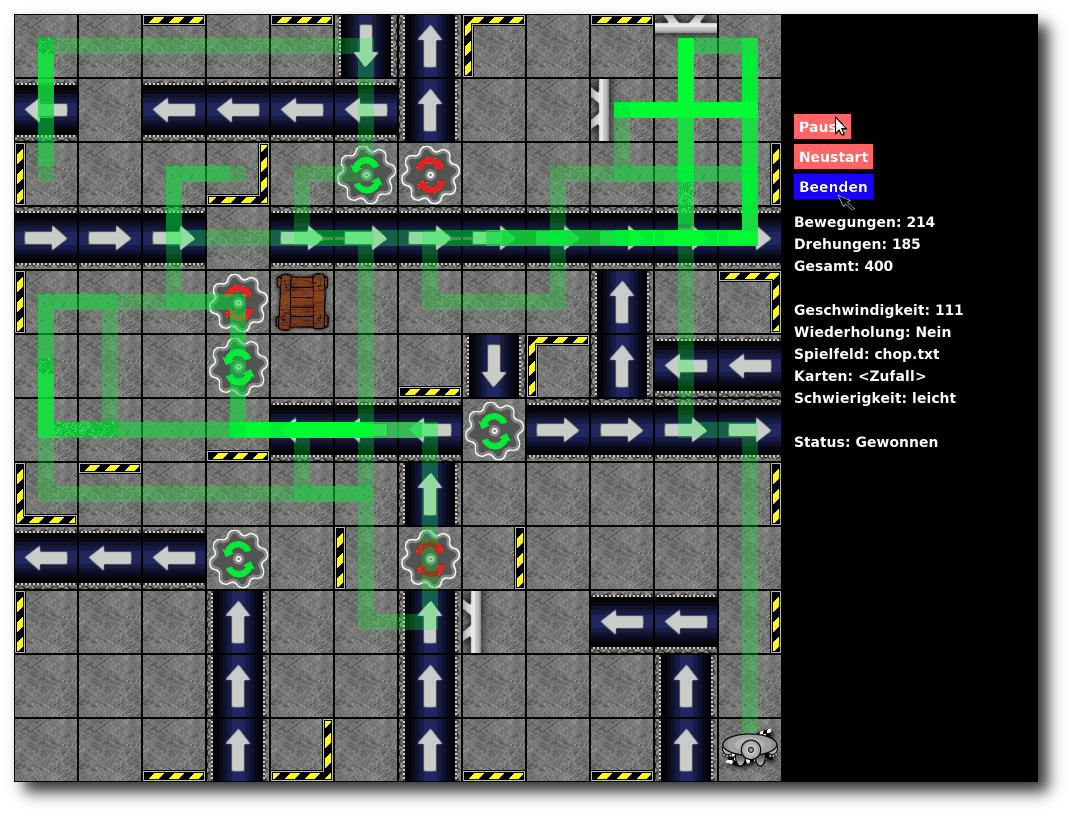
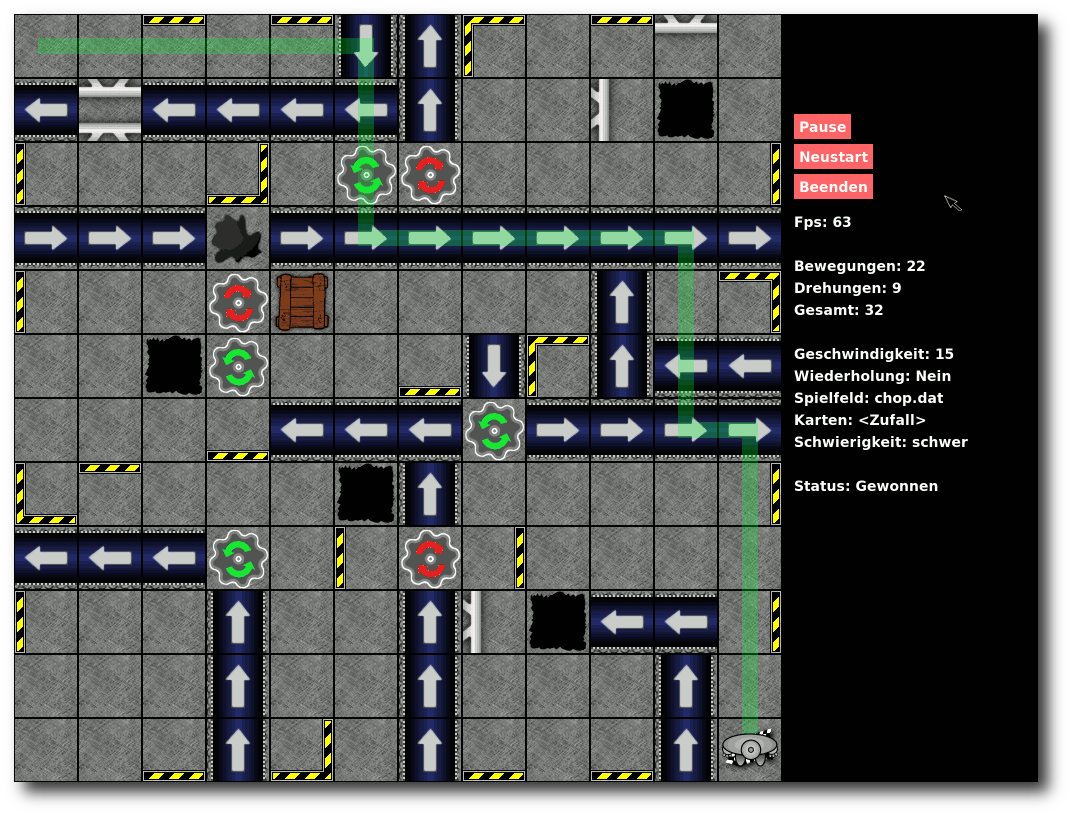
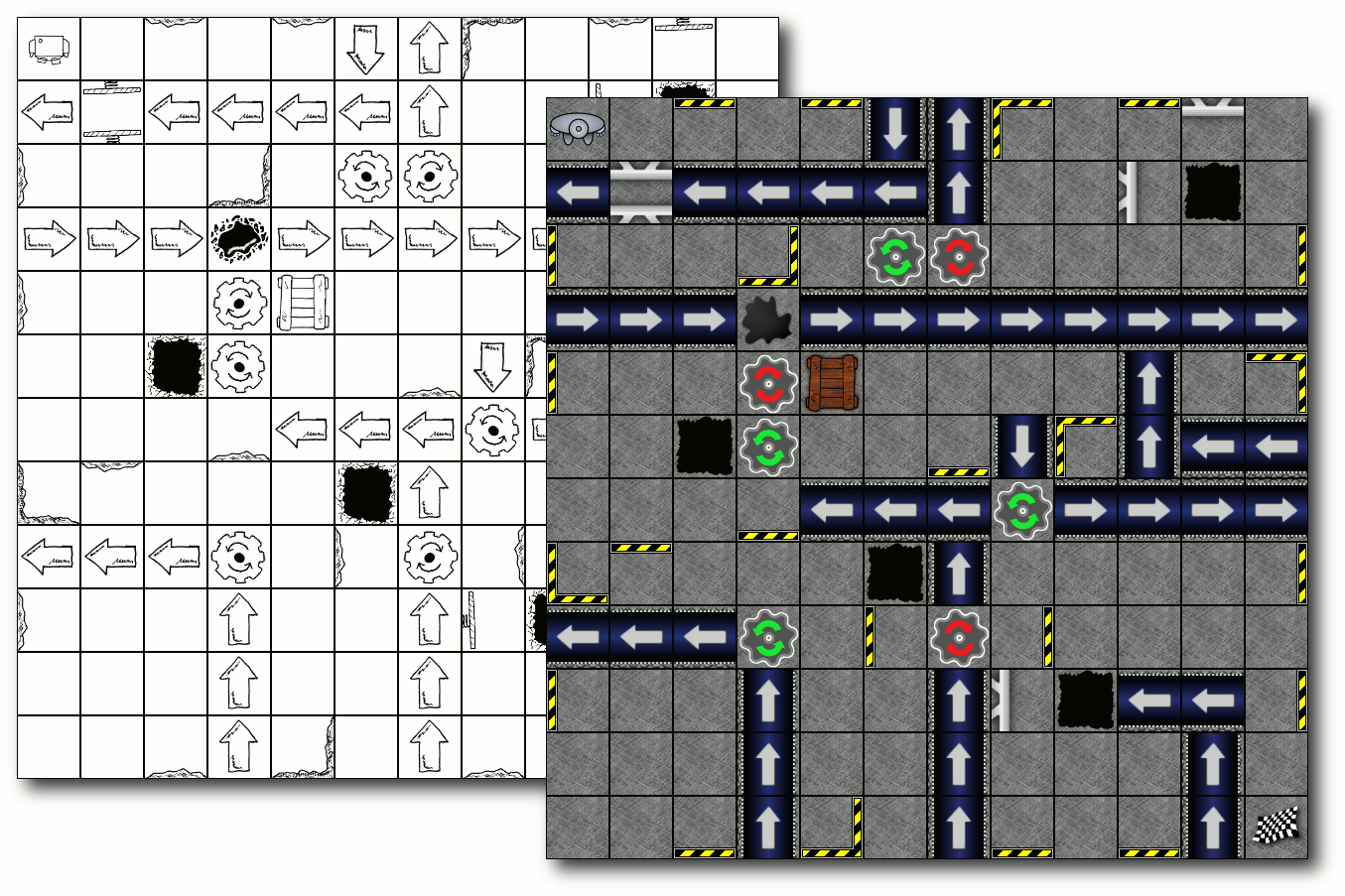
 | Boden: Wie langweilig! Ein leeres Fabrikfeld. |
 | Ziel: Das Zielfeld, zu dem der Roboter geführt werden muss. |
 | Wände: Wände wirken sehr einschränkend auf die Bewegungsfreiheit des Roboters, denn sie können nicht durchbrochen werden. Fährt ein Roboter gegen die Wand, passiert aber zumindest nichts Schlimmes (außer vielleicht einer kleinen Delle) |
 | Kiste: Eine Kiste sperrt ein Feld komplett. Man kann nicht anders, als das Hindernis zu umfahren. |
 | Loch: Wenn ein Roboter dieses Feld aus Versehen betritt oder darauf geschoben wird, verschwindet er auf Nimmerwiedersehen. |
 | Öl: Besonders glitschig! Wenn ein Roboter dieses betritt oder darauf geschoben wird, rutscht er bis zum nächsten Nichtölfeld weiter oder bis er von einer Wand gestoppt wird. Wenn er sich auf einem Ölfeld dreht, wird die Drehung verdoppelt. Aus einer Links- oder Rechtsdrehung wird zum Beispiel eine Drehung um 180 Grad. |
 | Drehrad: Drehwurm garantiert. Wenn man auf diesem Feld zum Stehen kommt, wird der Roboter um 90 Grad in die jeweils angezeigte Richtung gedreht. |
 | Förderband: Nur für Faule! Bleibt man auf einem Förderband stehen, bewegt es den Roboter einen Schritt in die jeweilige Richtung. Aufpassen sollte man hier, wenn am Ende der Abgrund wartet. |
 | Schieber: Deprimierend, ständig wird man durch die Gegend geschoben. Bleibt man vor dem Schieber stehen, schiebt er den Roboter ein Feld vorwärts. |
 | Schrottpresse: Zwischen den beiden Schiebern einer Schrottpresse sollte man nicht stehen bleiben, sonst landet man als kleiner zusammengepresster Würfel auf dem Müll. |
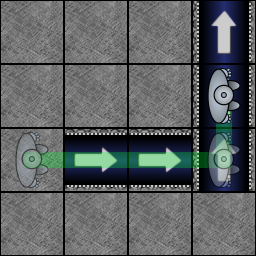
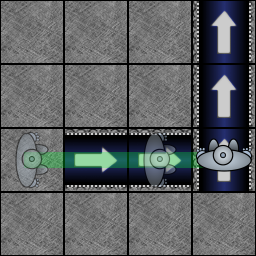
| Reihenfolge der Elementaktionen | |
| Reihenfolge | Aktion |
| 1 | Die Förderbänder bewegen sich. |
| 2 | Der Schieber und die Schrottpresse werden aktiviert. |
| 3 | Die Drehräder drehen sich. |
12 12 V e ev^f eF <N<<<<^ DH b k LR c >>>O>>>>>>>> b Rp ^ g HL ivf^<< i<<<L>>>> je H^ c <<<L bRc b ^ ^DH<<c ^ ^ ^ i^k ^i i^Z |
| Einfache Felder | |
| Zeichen | Feld |
| Leerzeichen | leerer Boden |
| H | Loch |
| O | Öl |
| S, T, U, V | Startfeld des Roboters (für die KI irrelevant, als leeres Bodenfeld behandeln) |
| Z | Zielfeld für den Roboter |
| Drehräder | |
| Zeichen | Feld |
| L | dreht den Roboter 90° gegen den Uhrzeigersinn |
| R | dreht den Roboter 90° im Uhrzeigersinn |
| Förderbänder | |
| Zeichen | Feld |
| < | Förderband nach links |
| > | Förderband nach rechts |
| ^ | Förderband nach oben |
| v | Förderband nach unten |
| Schieber/Presse | |
| Zeichen | Feld |
| C | schiebt den Roboter ein Feld nach links |
| D | schiebt den Roboter ein Feld nach rechts |
| E | schiebt den Roboter ein Feld nach oben |
| F | schiebt den Roboter ein Feld nach unten |
| M | Links/Rechts-Schrottpresse |
| N | Oben/Unten Schrottpresse |
| Wände | |
| Zeichen | Feld |
| a-p | definiert eine Wand/mehrere Wände pro Feld |
| Beispiele für Wände | ||
| Kodierung | Zeichen | Wände |
| 0 | a | keine |
| 1 | b | links |
| 8 | i | unten |
| 7 | h | links, rechts und oben |
| 15 | p | an allen vier Seiten (entspricht einer Kiste) |
7 8 D |

| Preisgelder | |
| Stufe | Preisgeld |
| leicht | 10 Euro |
| normal | 20 Euro |
| schwer | 30 Euro |
| 3-D-Spielbrett | 50 Euro |
$ make |
$ ./robots-engine save DECKNAME |
#!/bin/bash mkdir -p decks # create decks 0 - 99 for (( I=0; $I <= 99; I++ )) do echo "./robots-engine save decks/carddeck$I.dat" ./robots-engine save decks/carddeck$I.dat sleep 2 done |
$ ./robots-engine load BOARDNAME [easy|normal|hard] $ ./robots-engine load BOARDNAME DECKNAME [easy|normal|hard] |
$ ./robots-engine load gameboards/chop.dat decks/carddeck0.dat easy |
$ ./robots-engine start [easy|normal|hard] |
#!/bin/bash # Reference ./KIs/robots-ki-reference $1 retVal=$? exit $retVal |
./KIs/robots-ki-reference $1 |
#!/bin/bash GAMES=$1 DECKS=`find decks -name "*.dat" | sort` LEVEL=$2 date for GAME in $GAMES do for DECK in $DECKS do echo "./robots-contest $GAME $DECK $LEVEL" ./robots-contest $GAME $DECK $LEVEL done done date exit 0 |
$ ./start_contest GAMEBOARDS [easy|normal|hard] |
$ ./start_contest "gameboards/chop.dat gameboards/board2.dat" hard |
# gem install gosu |
ERROR: While executing gem ... (Gem::GemNotFoundException) Could not find gosu (> 0) in any repository |
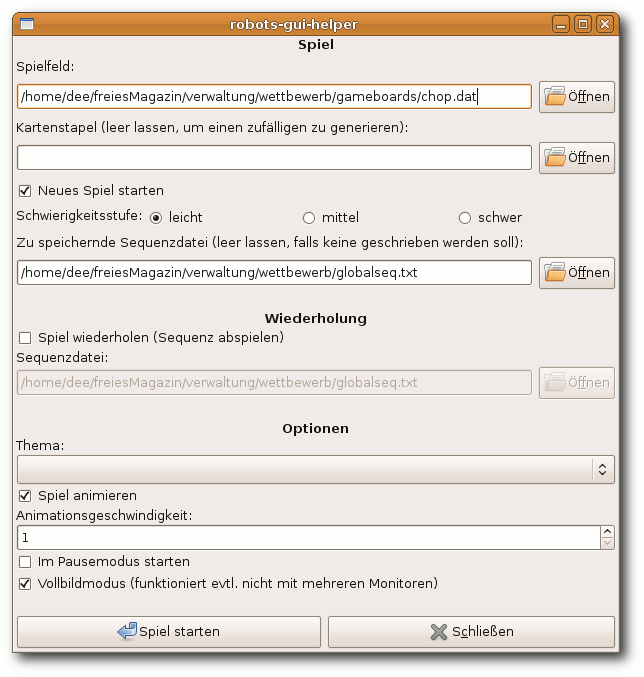
$ ./robots-gui-helper |
$ g++ -I./libbase -I./libcards -c main.cpp $ g++ -o ki.bin main.o -L./libbase -L./libcards -lcards -lbase |
| Messen | ||||
| Veranstaltung | Ort | Datum | Eintritt | Link |
| Linux Info Tag | Landau | 10.10.2009 | frei | http://infotag.lug-ld.de |
| Ubucon | Göttingen | 16.10.-18.10.09 | 15 EUR | http://www.ubucon.de |
| Linux-Kongress | Dresden | 27.10.-30.10.09 | - | http://www.linux-kongress.org/2009/ |
| The OpenSolaris Developer Conference | Dresden | 28.10.-30.10.09 | - | http://www.osdevcon.org/2009 |
| Linux Solution Day | Osnabrück | 29.10.2009 | frei | http://www.linux-solution-day.de |
| androidcamp | Berlin | 03.11.2009 | frei | http://androidcamp-berlin.mixxt.de/ |
| World Usability Day | Weltweit | 05.11.2009 | - | http://www.worldusabilityday.de |
| OpenRheinRuhr | Bottrop | 07.11.-08.11.09 | frei | http://openrheinruhr.de |
| Brandenburger Linux-Infotag | Potsdam | 21.11.2009 | frei | http://www.blit.org/2009 |
| $: | Shell-Prompt |
| #: | Prompt einer Root-Shell - Ubuntu-Nutzer können hier auch einfach in einer normalen Shell ein sudo vor die Befehle setzen. |
| ~: | Abkürzung für das eigene Benutzerverzeichnis /home/BENUTZERNAME |
Impressum ISSN 1867-7991 | ||
| freiesMagazin erscheint als PDF und HTML einmal monatlich. | ||
| Redaktionsschluss für die November-Ausgabe: 18. Oktober 2009 | ||
| Kontakt | ||
| Postanschrift | freiesMagazin | |
| c/o Dominik Wagenführ | ||
| Beethovenstr. 9/1 | ||
| 71277 Rutesheim | ||
| Webpräsenz | http://www.freiesmagazin.de | |
| Autoren dieser Ausgabe | ||
| Raoul Falk | Java, Teil 1 - Einführung in eine moderne Sprache | |
| Florian E.J. Fruth | Grundbegriffe der Virtualisierung | |
| Martin Gräßlin | Gefahren von Fremdquellen am Beispiel PPA | |
| Steve Klicek | Kurztipp: Suchen und Finden mit Vim | |
| Rainer König | Ordnung ins Chaos mit Org-Mode | |
| Marcel Jakobs | Von der Schaltung zur fertigen Platine mit EAGLE | |
| Mathias Menzer | Der September im Kernelrückblick | |
| Dominik Wagenführ | 41. DANTE-Mitgliedertagung in Esslingen | |
| Philipp Walther | grep - Eine kleine Einführung | |
| Erscheinungsdatum: 4. Oktober 2009 | ||
| Erstelldatum: 6. Oktober 2009 | ||
| Redaktion | ||
| Dominik Honnef | Thorsten Schmidt | |
| Dominik Wagenführ (Verantwortlicher Redakteur) | ||
| Satz und Layout | ||
| Ralf Damaschke | Yannic Haupenthal | |
| Marcus Nelle | Markus Schaub | |
| Sebastian Schlawtow | ||
| Korrektur | ||
| Daniel Braun | Raoul Falk | |
| Stefan Fangmeier | Lukas Martini | |
| Johannes Mitlmeier | Karsten Schuldt | |
| Veranstaltungen | ||
| Ronny Fischer | ||
| Logo-Design | ||
| Arne Weinberg (GNU FDL) | ||
{kind=link}