













Impressum ISSN 1867-7991 | ||
| freiesMagazin erscheint als PDF und HTML einmal monatlich. | ||
| Redaktionsschluss für die Januar-2010-Ausgabe: 16. Dezember 2010 | ||
| Kontakt | ||
| Postanschrift | freiesMagazin | |
| c/o Dominik Wagenführ | ||
| Beethovenstr. 9/1 | ||
| 71277 Rutesheim | ||
| Webpräsenz | http://www.freiesmagazin.de/ | |
| Autoren dieser Ausgabe | ||
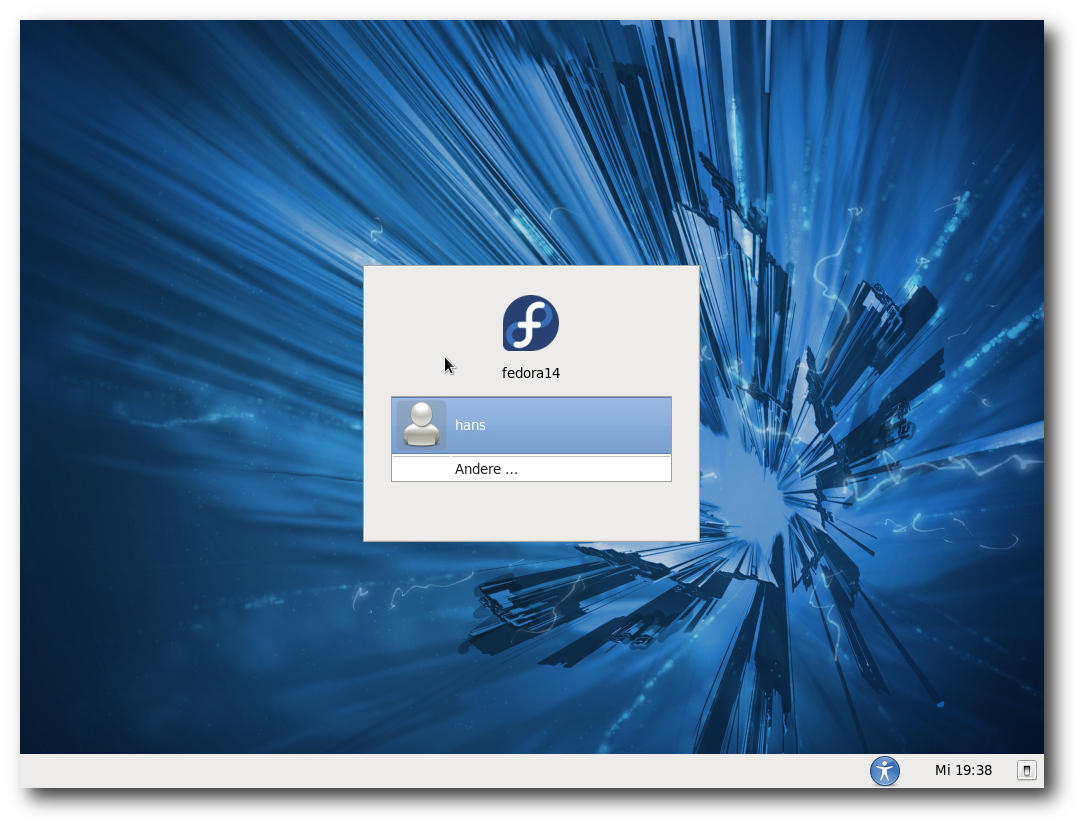
| Hans-Joachim Baader | Fedora 14 | |
| Florin Bottke | Invertika – ein Open-Source-MMORPG | |
| Martin Gräßlin | Ubuntu Developer Summit 2010 | |
| Marc Hildebrandt | Nepomuk in KDE – Theorie und Praxis | |
| Jonas Knudsen | ALSA konfigurieren | |
| Mathias Menzer | Der November im Kernelrückblick | |
| Michael Niedermair | Rezension: iText in action – Second Edition | |
| Daniel Nögel | Python-Programmierung: Teil 3 – Funktionen und Module | |
| Stefan Ohri | Bildformat SVG verstehen | |
| Jochen Schnelle | Rezenzion: Phrasebooks | |
| Andreas Schott, Martin Neubauer und Ralf Hufnagel | easyVDR 0.8 – HDTV-Version veröffentlicht | |
| Dominik Wagenführ | Rezension: Sintel | |
| Erscheinungsdatum: 5. Dezember 2010 | ||
| Redaktion | ||
| Frank Brungräber | Thorsten Schmidt | |
| Dominik Wagenführ (Verantwortlicher Redakteur) | ||
| Satz und Layout | ||
| Ralf Damaschke | Yannic Haupenthal | |
| Nico Maikowski | Matthias Sitte | |
| Korrektur | ||
| Daniel Braun | Stefan Fangmeier | |
| Mathias Menzer | Karsten Schuldt | |
| Stephan Walter | ||
| Veranstaltungen | ||
| Ronny Fischer | ||
| Logo-Design | ||
| Arne Weinberg (GNU FDL) | ||
Soweit nicht anders angegeben, stehen alle Artikel, Beiträge und Bilder in freiesMagazin unter der Creative-Commons-Lizenz CC-BY-SA 3.0 Unported. Das Copyright liegt beim jeweiligen Autor. freiesMagazin unterliegt als Gesamtwerk ebenso der Creative-Commons-Lizenz CC-BY-SA 3.0 Unported mit Ausnahme der Inhalte, die unter einer anderen Lizenz hierin veröffentlicht werden. Das Copyright liegt bei Dominik Wagenführ. Es wird erlaubt, das Werk/die Werke unter den Bestimmungen der Creative-Commons-Lizenz zu kopieren, zu verteilen und/oder zu modifizieren. Das freiesMagazin-Logo wurde von Arne Weinberg erstellt und unterliegt der GFDL. Die xkcd-Comics stehen separat unter der Creative-Commons-Lizenz CC-BY-NC 2.5 Generic. Das Copyright liegt bei Randall Munroe.
Zum Index