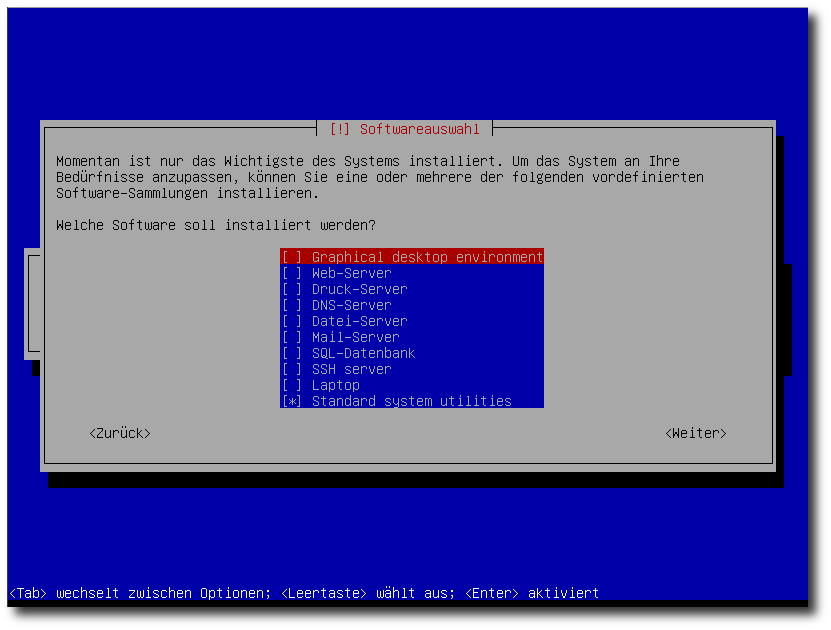
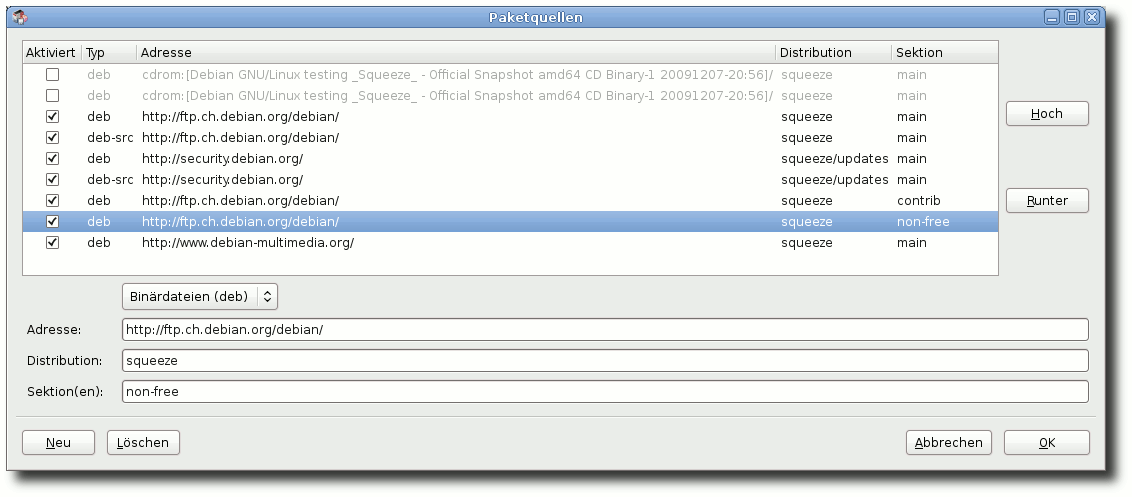
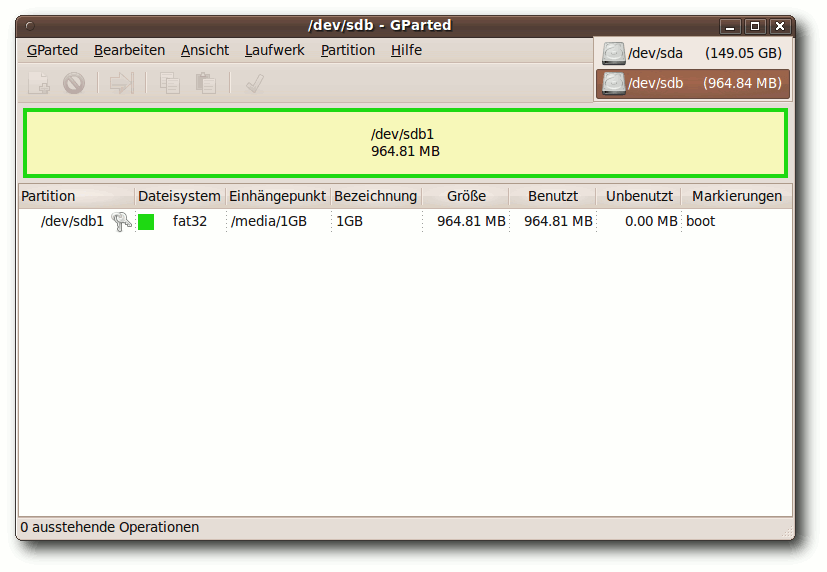
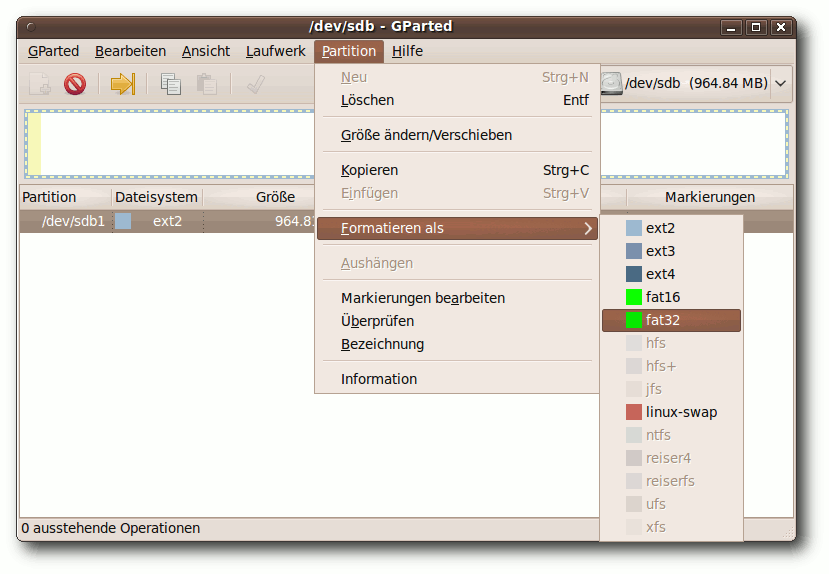
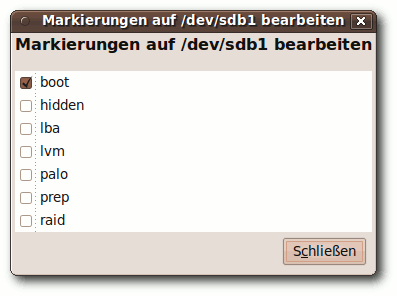
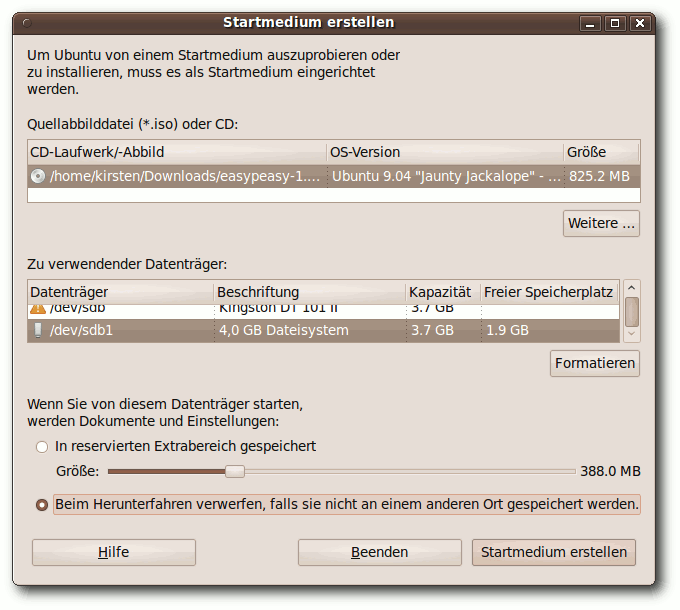
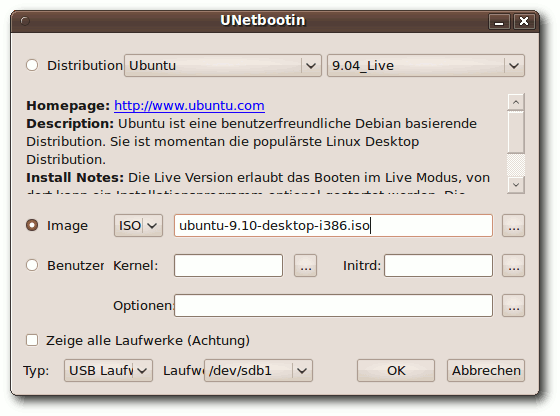
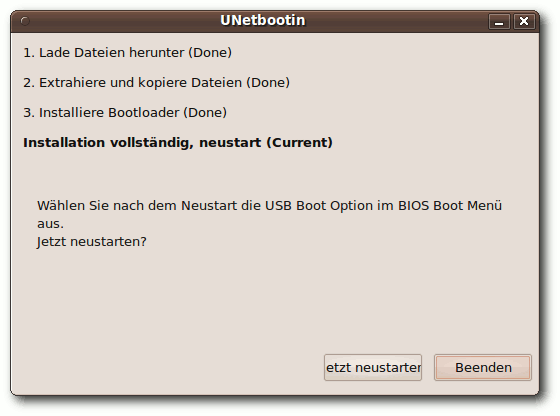
|
| Erscheinungsdatum: 2. April 2010 |
|
|
| Redaktion |
| Dominik Honnef | Thorsten Schmidt |
| Dominik Wagenführ (Verantwortlicher Redakteur) |
| |
| Satz und Layout |
| Ralf Damaschke | Yannic Haupenthal |
| Michael Niedermair | |
| |
| Korrektur |
| Daniel Braun | Frank Brungräber |
| Stefan Fangmeier | Mathias Menzer |
| Karsten Schuldt | Franz Seidl |
| Stephan Walter | |
| |
| Veranstaltungen |
| Ronny Fischer |
| |
| Logo-Design |
| Arne Weinberg (GNU FDL) |
| |
Dieses Magazin wurde mit LaTeX erstellt. Mit vollem Namen
gekennzeichnete Beiträge geben nicht notwendigerweise die Meinung
der Redaktion wieder. Wenn Sie
freiesMagazin ausdrucken möchten, dann
denken Sie bitte an die Umwelt und drucken Sie nur im Notfall. Die
Bäume werden es Ihnen danken. ;-)
Soweit nicht anders angegeben, stehen alle Artikel und Beiträge in
freiesMagazin unter der
GNU-Lizenz für freie Dokumentation (FDL). Das Copyright liegt
beim jeweiligen Autor.
freiesMagazin unterliegt als Gesamtwerk ebenso
der
GNU-Lizenz für freie Dokumentation (FDL) mit Ausnahme von
Beiträgen, die unter einer anderen Lizenz hierin veröffentlicht
werden. Das Copyright liegt bei Dominik Wagenführ. Es wird die
Erlaubnis gewährt, das Werk/die Werke (ohne unveränderliche
Abschnitte, ohne vordere und ohne hintere Umschlagtexte) unter den
Bestimmungen der GNU Free Documentation License, Version 1.2 oder
jeder späteren Version, veröffentlicht von der Free Software
Foundation, zu kopieren, zu verteilen und/oder zu modifizieren.
Die xkcd-Comics stehen separat unter der
Creative-Commons-Lizenz CC-BY-NC 2.5. Das Copyright liegt
bei
Randall Munroe.
Zum Index