






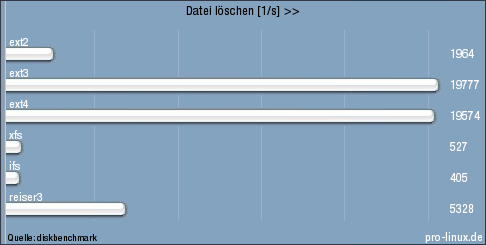




 Die Zählung der Spielfeldindizes beginnt typisch für C++ (Referenzimplementierung) bei 0, sodass die x- und y-Werte von 0 bis 9 laufen.
Der Spieler, der an der Reihe ist, hat verschiedene Möglichkeiten, einen gültigen Zug durchzuführen. Er kann z. B. Feld (0,8) mit (0,9) tauschen, was drei blaue Steine horizontal zusammenfügt, oder (6,7) mit (5,7), was drei rote Steine vertikal aneinanderreiht. Die Referenz-KI tauscht aber die Felder (1,0) mit (1,1), um drei lilafarbene Steine zusammenzufügen.
Die drei lilafarbenen Steine werden seinem Konto gut geschrieben und verschwinden.
Alle darüberliegenden Steine rutschen ein Feld nach unten, was oben eine Lücke entstehen lässt, welche durch neue Steine aufgefüllt wird:
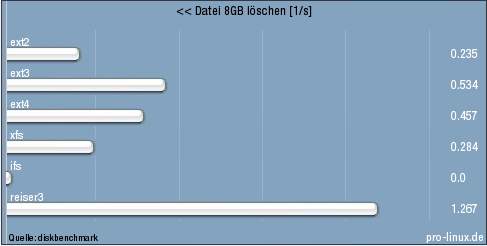
Die Zählung der Spielfeldindizes beginnt typisch für C++ (Referenzimplementierung) bei 0, sodass die x- und y-Werte von 0 bis 9 laufen.
Der Spieler, der an der Reihe ist, hat verschiedene Möglichkeiten, einen gültigen Zug durchzuführen. Er kann z. B. Feld (0,8) mit (0,9) tauschen, was drei blaue Steine horizontal zusammenfügt, oder (6,7) mit (5,7), was drei rote Steine vertikal aneinanderreiht. Die Referenz-KI tauscht aber die Felder (1,0) mit (1,1), um drei lilafarbene Steine zusammenzufügen.
Die drei lilafarbenen Steine werden seinem Konto gut geschrieben und verschwinden.
Alle darüberliegenden Steine rutschen ein Feld nach unten, was oben eine Lücke entstehen lässt, welche durch neue Steine aufgefüllt wird:
 Im nächsten Zug böte es sich für den zweiten Spieler an, Feld (2,2) mit (3,2) zu tauschen, damit der erste Spieler 10 Punkte (5 + 4 + 1) Schaden erleidet.
Im nächsten Zug böte es sich für den zweiten Spieler an, Feld (2,2) mit (3,2) zu tauschen, damit der erste Spieler 10 Punkte (5 + 4 + 1) Schaden erleidet.
Impressum ISSN 1867-7991 | ||
| freiesMagazin erscheint als PDF und HTML einmal monatlich. | ||
| Redaktionsschluss für die Mai-Ausgabe: 22. April 2009 | ||
| Kontakt | ||
| Postanschrift | freiesMagazin | |
| c/o Dominik Wagenführ | ||
| Beethovenstr. 9/1 | ||
| 71277 Rutesheim | ||
| Webpräsenz | http://www.freiesmagazin.de | |
| freiesMagazin-Team (Teamaufschlüsselung) | ||
| Raoul Falk | ||
| Stephan Hochhaus | ||
| Ekkehard Hollmann | ||
| Dominik Honnef | ||
| Mathias Menzer | ||
| Thorsten Schmidt | ||
| Karsten Schuldt | ||
| Dominik Wagenführ | ||
| (Verantwortlicher Redakteur) | ||
| Erscheinungsdatum: 5. April 2009 | ||
| Autoren dieser Ausgabe | ||
| Benedikt Ahrens | ||
| Hans-Joachim Baader | ||
| Raoul Falk | ||
| Matthias Kietzke | ||
| Mathias Menzer | ||
| Bernd Noetscher | ||
| Florian Schweikert | ||
| Dominik Wagenführ | ||
| Veranstaltungen | ||
| Ronny Fischer | ||
| Logo-Design | ||
| Arne Weinberg | ||
| Lizenz | GNU FDL | |
Soweit nicht anders angegeben, stehen alle Artikel und Beiträge in freiesMagazin unter der GNU-Lizenz für freie Dokumentation (FDL). Das Copyright liegt beim jeweiligen Autor. freiesMagazin unterliegt als Gesamtwerk ebenso der GNU-Lizenz für freie Dokumentation (FDL) mit Ausnahme von Beiträgen, die unter einer anderen Lizenz hierin veröffentlicht werden. Das Copyright liegt bei Eva Drud. Es wird die Erlaubnis gewährt, das Werk/die Werke (ohne unveränderliche Abschnitte, ohne vordere und ohne hintere Umschlagtexte) unter den Bestimmungen der GNU Free Documentation License, Version 1.2 oder jeder späteren Version, veröffentlicht von der Free Software Foundation, zu kopieren, zu verteilen und/oder zu modifizieren. Die xkcd-Comics stehen separat unter der Creative Commons-Lizenz CC-BY-NC 2.5. Das Copyright liegt bei Randall Munroe.
Zum Index